
YOLO5自制数据集
本文设计的代码与素材均在这里,如果对您有帮助,欢迎start
1.打标签
执行labelImg.exe,制作xml数据集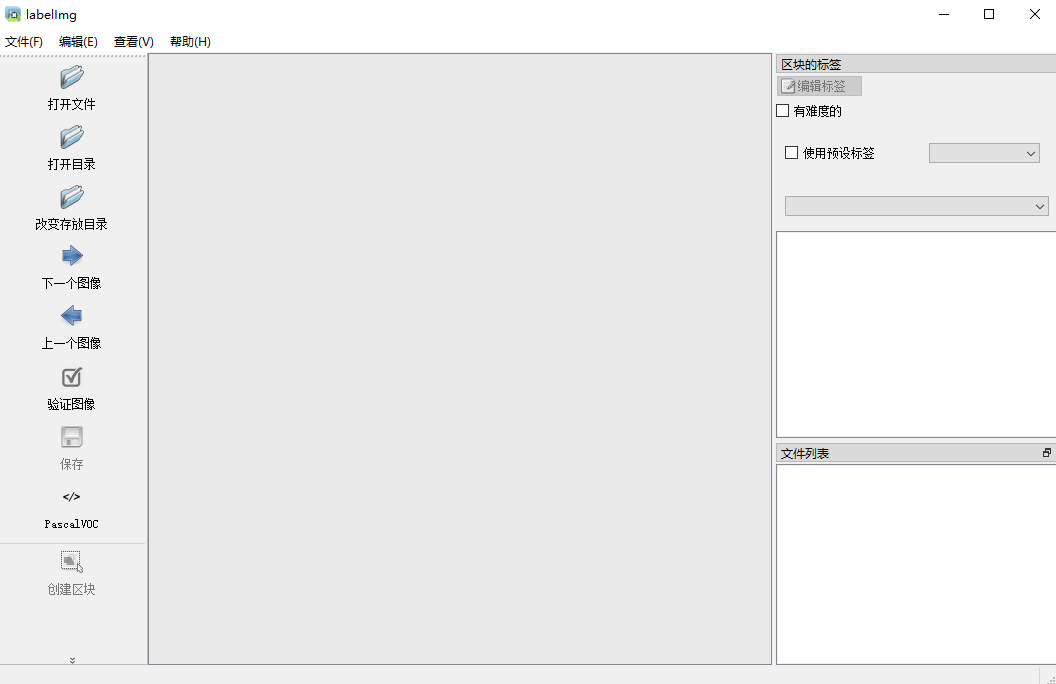
2.构建VOC2007目录
将标注好的xml文件放在Annotations目标中
将图片放在JPEGImages中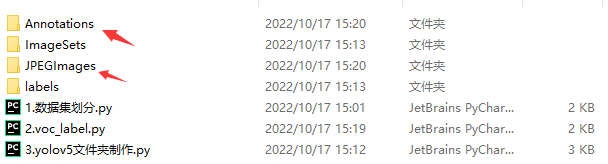
3.用python依次执行1,2,3,后面会提供1,2,3程序
注意:执行1.数据集划分.py之前需要修改数据集划分的比例(可以不修改)
注意:执行2.voc_label.py之前需要修改类别(必须修改)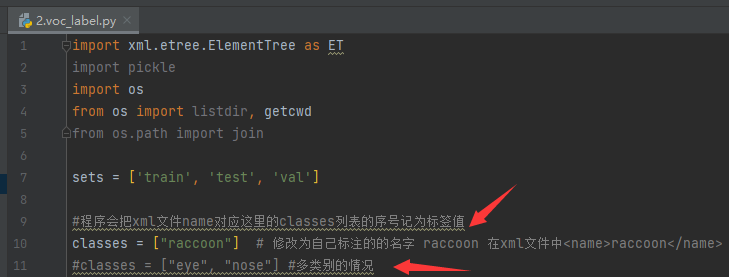
依次执行1,2,3py文件,会生成一堆其他文件和这个yolo5_data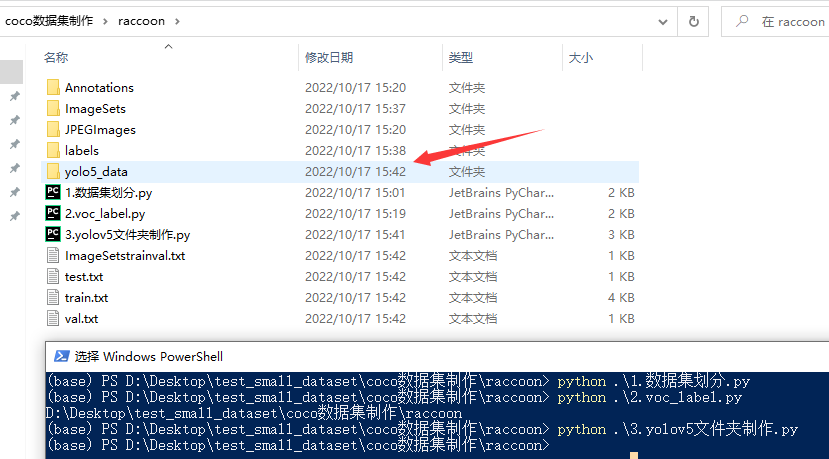
将生成的uolo5_data拷贝到yolo项目
4.在YOLO5项目的data目录中新建自己的yaml文件
写入下面内容nc为分类数量,name是标签名字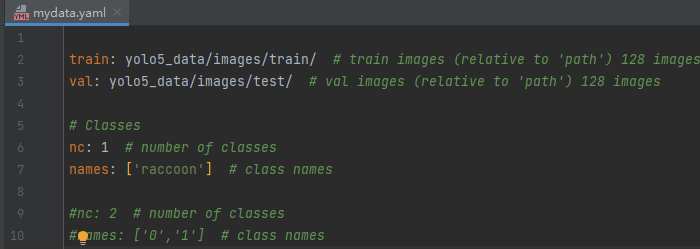
5.修改train.py文件
1处需要打开到对应的文件models/yolo5s.yaml文件,修改为分类数量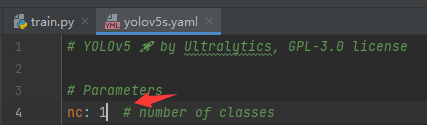
2处需要改为前面新建的yaml的名字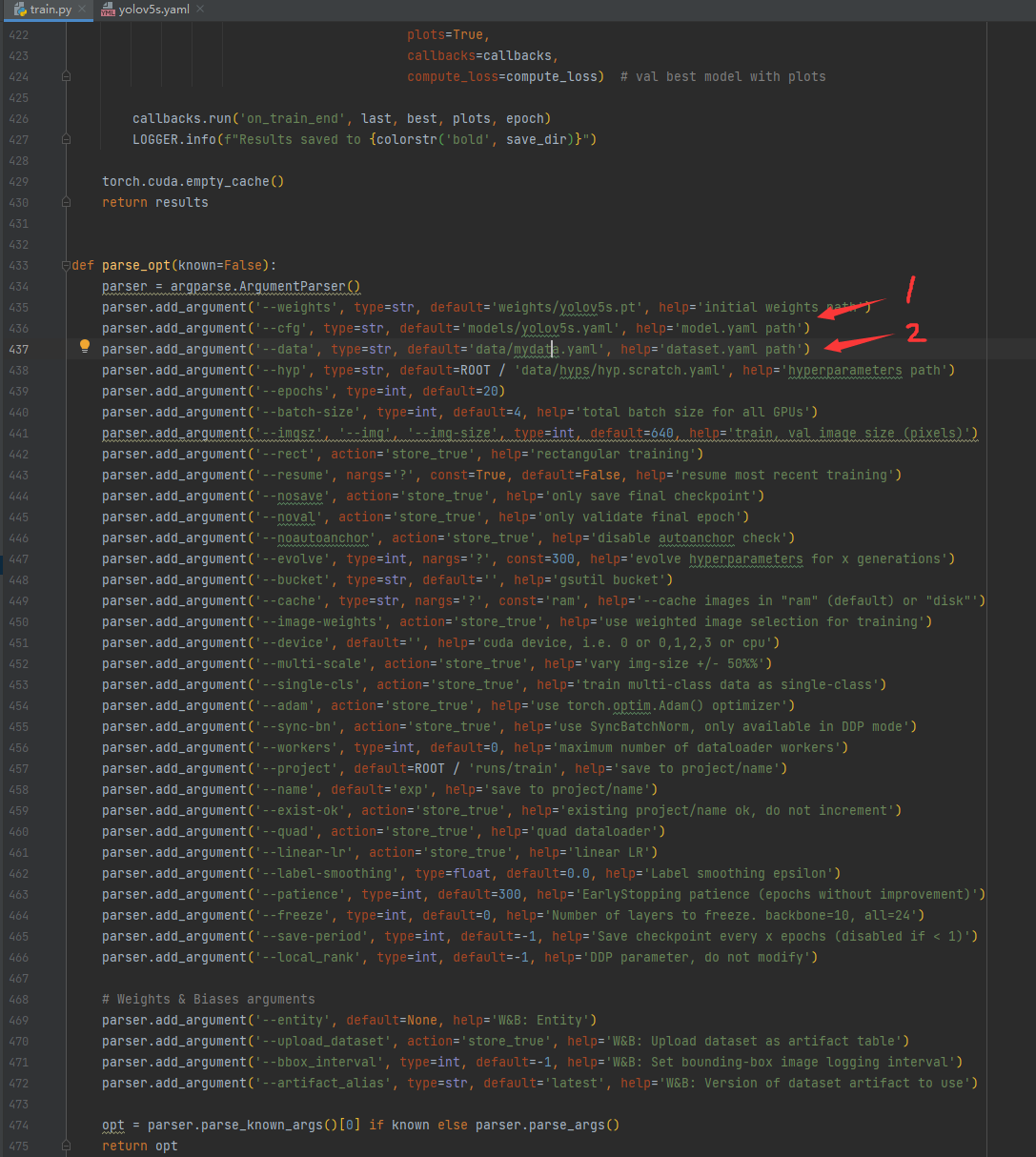
6.开始训练执行train.py
若是第一次配置
1%执行train.py文件就可以开始训练自己的数据集
99%的可能出现错误,比如:显存不足,模型权重版本不正确,电脑环境没配置好。要根据报错信息具体分析。
如果你觉得本文对你有所帮助,别忘记给我点个start,有任何疑问和想法,欢迎在评论区与我交流。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 爱吃糖的猫!
 微信
微信 支付宝
支付宝
相关推荐

评论






