应用 DeepFake是指使用深度学习技术生成逼真的伪造视频、音频或图像,从而让人产生一种虚假的印象。尽管DeepFake技术有一些负面的应用,但也有一些潜在的正面应用。以下是一些DeepFake技术的应用领域:
娱乐业:DeepFake可以用于电影、电视剧或广告中的特效制作,使角色看起来更加逼真或实现特殊效果。
影视修复:DeepFake可以用于修复旧电影或照片中的损坏或缺失的部分,使其看起来更加完整。
视频游戏:DeepFake可以用于游戏中的角色动画,使其动作和表情更加逼真。
艺术创作:DeepFake可以用于创意艺术作品的生成,例如生成逼真的数字艺术或虚拟角色。
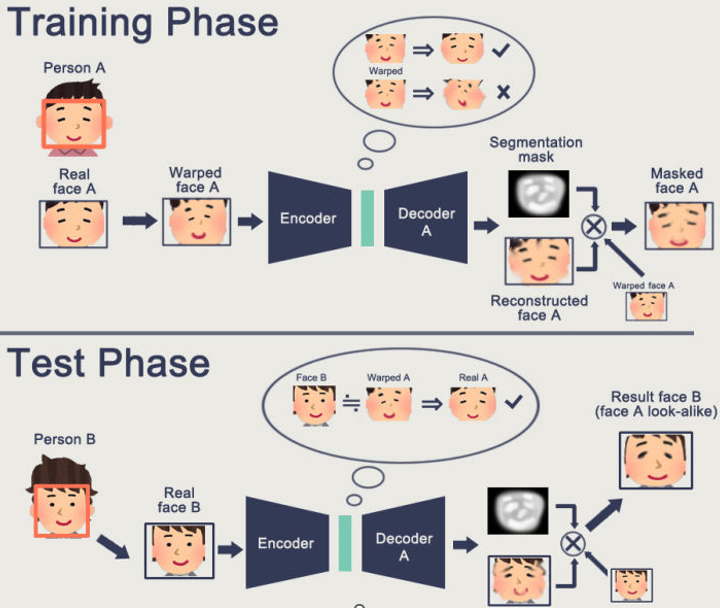
原理 换脸原理:用监督学习训练一个神经网络将张三的扭曲处理过的脸还原成原始脸,并且期望这个网络具备将任意人脸还原成张三的脸的能力。
自编码机(AutoEncoder) 自编码器是一种能够通过无监督学习,学到输入数据高效表示的人工神经网络。输入数据的这一高效表示称为编码,其维度一般远小于输入数据,使得自编码器可用于降维。更重要的是,自编码器可作为强大的特征检测器(feature detectors),应用于深度神经网络的预训练。此外,自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型(generative model)。
Deepfake实现流程:一提取数据,二训练,三转换。其中第一和第三步都需要用到数据预处理,另外第三步还用到了图片融合技术。
代码解析 目录结构
图像预处理 从大图中识别,并抠出人脸图像,根据这些坐标能计算人脸的角度,最终抠出来的人脸是摆正后的人脸。
def random_warp (image ): assert image.shape == (256 , 256 , 3 ) range_ = numpy.linspace(128 - 80 , 128 + 80 , 5 ) mapx = numpy.broadcast_to(range_, (5 , 5 )) mapy = mapx.T mapx = mapx + numpy.random.normal(size=(5 , 5 ), scale=5 ) mapy = mapy + numpy.random.normal(size=(5 , 5 ), scale=5 ) interp_mapx = cv2.resize(mapx, (80 , 80 ))[8 :72 , 8 :72 ].astype('float32' ) interp_mapy = cv2.resize(mapy, (80 , 80 ))[8 :72 , 8 :72 ].astype('float32' ) warped_image = cv2.remap(image, interp_mapx, interp_mapy, cv2.INTER_LINEAR) src_points = numpy.stack([mapx.ravel(), mapy.ravel()], axis=-1 ) dst_points = numpy.mgrid[0 :65 :16 , 0 :65 :16 ].T.reshape(-1 , 2 ) mat = umeyama(src_points, dst_points, True )[0 :2 ] target_image = cv2.warpAffine(image, mat, (64 , 64 )) return warped_image, target_image
模型结构 class Autoencoder (nn.Module): def __init__ (self ): super (Autoencoder, self).__init__() self.encoder = nn.Sequential( _ConvLayer(3 , 128 ), _ConvLayer(128 , 256 ), _ConvLayer(256 , 512 ), _ConvLayer(512 , 1024 ), Flatten(), nn.Linear(1024 * 4 * 4 , 1024 ), nn.Linear(1024 , 1024 * 4 * 4 ), Reshape(), _UpScale(1024 , 512 ), ) self.decoder_A = nn.Sequential( _UpScale(512 , 256 ), _UpScale(256 , 128 ), _UpScale(128 , 64 ), Conv2d(64 , 3 , kernel_size=5 , padding=1 ), nn.Sigmoid(), ) self.decoder_B = nn.Sequential( _UpScale(512 , 256 ), _UpScale(256 , 128 ), _UpScale(128 , 64 ), Conv2d(64 , 3 , kernel_size=5 , padding=1 ), nn.Sigmoid(), ) def forward (self, x, select='A' ): if select == 'A' : out = self.encoder(x) out = self.decoder_A(out) else : out = self.encoder(x) out = self.decoder_B(out) return out
图像融合 成功训练之后,自动编码机会将截取下来的明星A的脸部细节换成明星B的脸部,同时保留A的眼睛,鼻子,嘴巴的位置以及表情,最后一步是需要将换好的脸部截图贴回原图,并与原图天衣无缝的融合。
images_A = get_image_paths("data/trump" ) images_B = get_image_paths("data/cage" ) images_A = load_images(images_A) / 255.0 images_B = load_images(images_B) / 255.0 images_A += images_B.mean(axis=(0 , 1 , 2 )) - images_A.mean(axis=(0 , 1 , 2 ))
效果
总结 源码点这 ,autoencoder.t7文件点这 ,本本环境使用的pytorch1.1,其他版应该也是兼容的。
如果你觉得本文对你有所帮助,别忘记给我点个start,有任何疑问和想法,欢迎在评论区与我交流。


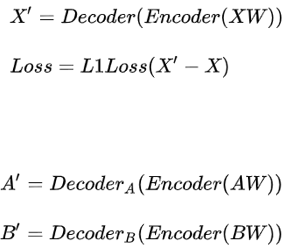


 微信
微信 支付宝
支付宝






